SSD
SSD(Single Shot multibox Detector)
background
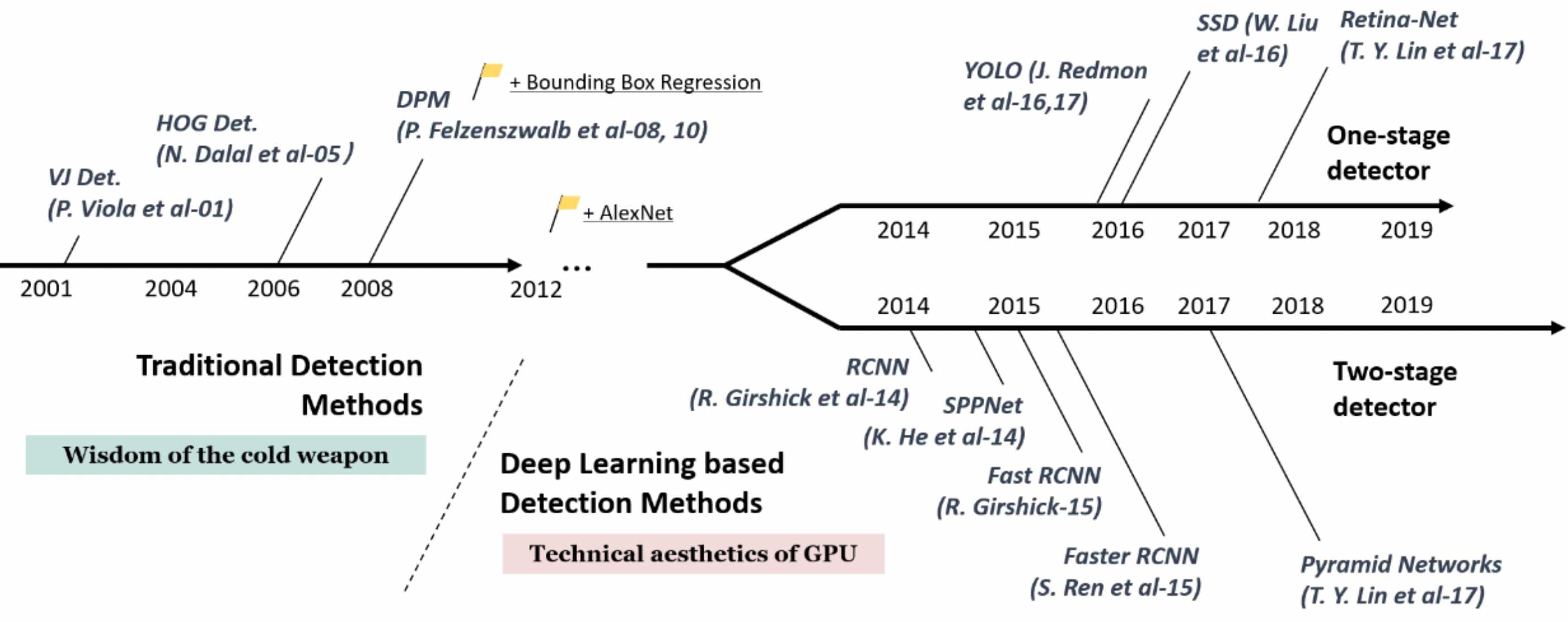
- one stage vs two stage : Resion proposal이 별도로 구성되어있느냐 없느냐의 차이.
- two stage detector 중 Faster RCNN이 비교적 빠른 속도임에도 불구하고 실시간으로 사용하기에는 무리가 있음.
- object detection의 inference time을 줄이기 위해 one stage에 대해 학습.
- YOLO로 인해 inference time은 향상되었으나 mAP가 떨어짐.
- 뒤이어 나온 SSD가 inference time도 좋고 mAP가 Faster RCNN보다 좋은 모델.
SSD 주요 구성 요소
- Feature Map 기반 Multi Scale Feature Layer
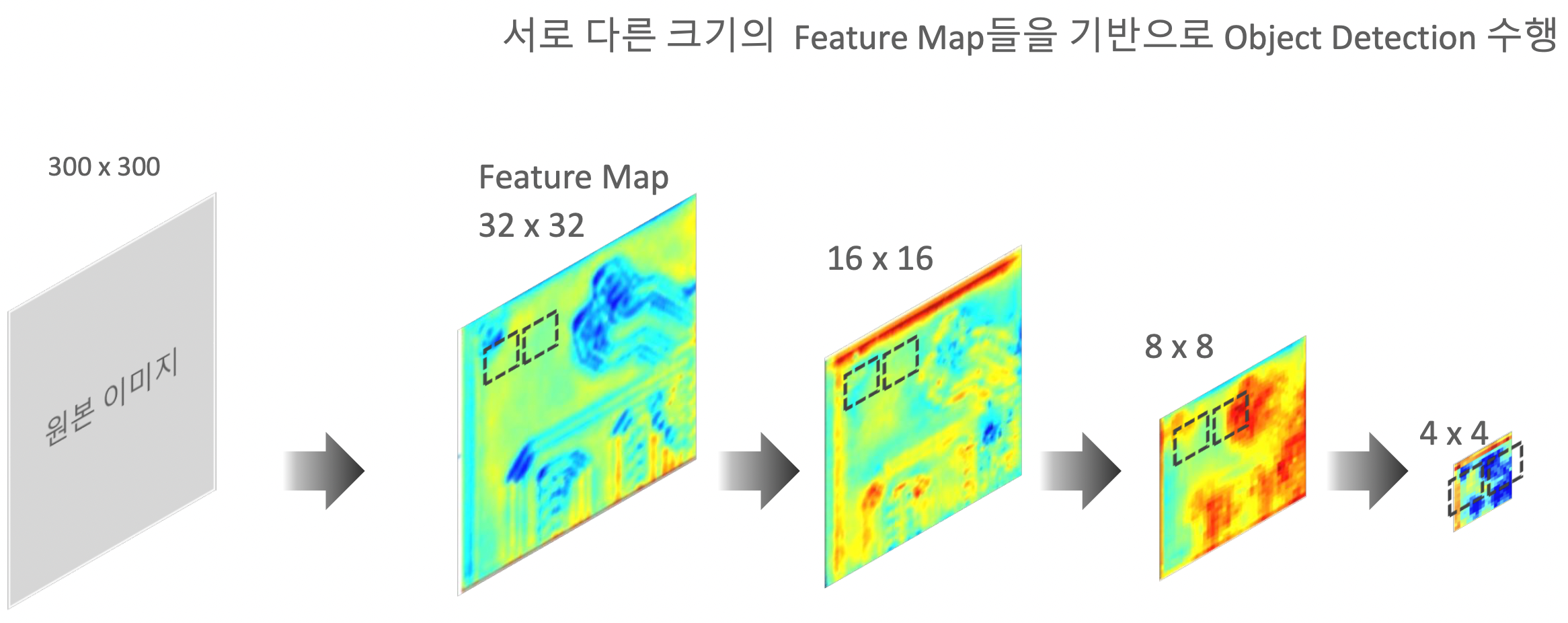
- Sliding Window를 기반으로 응용
- 큰 feature map의 경우 원본 이미지에 가까운 특징들을 가지고 있고, 비교적 작은 사이즈의 Object를 detect하기 용이.
- 거듭 CNN을 진행한 더 작은 feature map의 경우 더 추상적이고 핵심적인 특징들을 가지고 있고, 비교적 큰 사이즈의 Object를 detect하기 용이.
- Default (Anchor) Box
- 기존 Faster RCNN 중 RPN의 경우, Classification & Bounding box Regression을 진행함
- 이를 object detection에 바로 활용
- 각 grid 별로 형성된 anchor box들에 대해 개별적으로 object 유형에 따른 softmax 및 좌표값을 계산
- Conv 결과값은 object class 별 probability + background + offset 4 points 값을 갖게 됨.
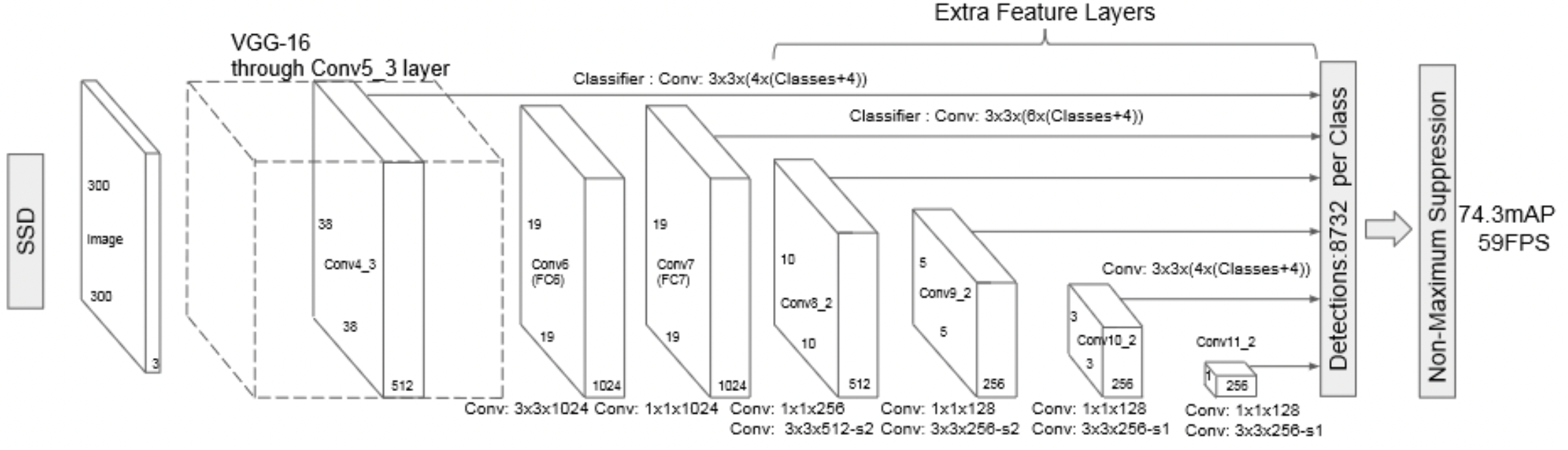
Doubt
자 IoU = Ground Truth와 bounding box와의 겹치는 영역의 비를 나타낸건데 지금 SSD에서 NMS를 적용하는 부분은 각 feature map에서 확인된 anchor box들에 대해서 적용하는 거임 따라서 NMS는 다수의 anchor box vs Ground truth 간 confidence score 및 IoU를 이용해서 하는건데
feature map에서 확인된 anchor box는 resizing이 된건데 ground truth와 어떻게 비교하지?
matching strategy
사실 앞에서 만든 feature map 별 anchor box가 너무 많기 때문에 NMS를 통해서 수를 극적으로 줄여서 inference time을 개선
match 전략 : bounding box와 anchor box와의 IoU보는거래 그럼 결국 아래의 두가지 경우를 모두 보는 거 아닌가? 처음에 말했던 컨셉이 충돌되는 거 같은데
- feature map anchor box vs ground truth IoU
- feature map anchor box vs bounding box IoU
feature map에 anchor box를 적용했을 때의 문제점은 크기가 작은 object를 detect했을 때의 성능이 떨어짐
이에 대한 성능 보정을 위해 Data Augmentation을 진행
Data Augmentation
- 학습 데이터셋의 규모를 키우는 방법
- 원본에 추가되는 개념이라 성능이 떨어지지 않음
- 단기간에 성능을 올리고 싶은 경우 적용
- 데이터가 많아진다는 것은 overfitting을 줄일 수 있다는 것을 의미
- 대부분 학습에 사용된 데이터의 품질은 좋지만 실제 테스트에 사용될 데이터들은 노이즈 등이 있어서 예측이 어려울 수 있음. 즉, 모델이 실제 환경에서도 잘 동작하도록 도와줌.
- Mirroring
- Random Cropping
- Rotating
- Color shifting
- Shearing
- etc …