Object Detection과 Segmentation
0. Dependancy
- CNN
- feature extractor network(convolution, kernel(filter), pooling, feature map)
- VGG, rasnet etc
- 2012년도에 AlexNet이 ImageNet compatition에서 DL기반의 CNN을 사용
- 이 시점을 기준으로 DL에 대한 performance 등 여러 가능성이 증가함
1. Definition
Classification
- feature map과 label 등의 정보를 이용하여 이미지 분류
Localization
- 이미지 안에서 특정 영역을 한정 짓는 것
- 하나의 이미지에 하나의 object를 bounding box로 지정하여 예측
Detection
- 하나의 이미지에 다수의 Object
- 각 objectfmf bounding box로 구분하여 예측
- Region proposal과 classification
- 동시에 진행되면 1stage detector
- region proposal > classification이 순차적으로 진행되면 2stage detector
- 포인트는 성능과 수행 시간이 반비례
Segmentation
- Detection에서 bounding box단위가 아니라 pixel 단위로 구분
2. Overview of Object Detection
- Region proposal
- DL network
- Feature extractor network
- FPN
- feature extractor와 prediction network를 연결
- 작은 object들에 대한 정보를 체계화시켜 분류
- Object가 크다는 전제조건이 있다면 무시할 수도 있을지도..
- Object Detection network
- 기타 요소
- IoU
- NMS
- mAP
- Anchor Box
- etc …
- Issue
- Classification + Regression을 동시에 진행
- 다양한 크기의 object
- Detection time
- 명확하지 않은 이미지
- train data set 부족(Annotation)
3. Overview of Object Localization
- 단일 이미지의 localization의 경우 비교적 쉬움
- classification의 flow와 동일한데, bounding box에 대한 regression이 추가됨
- bounding box에 대한 annotation file이 별도로 필요
- 좌표값을 나타내는 annotation file의 경우 데이터셋 및 알고리즘에 따라 차이가 있을 수 있음.
- 결과는 예측 class에 따른 confidence(class) score와 bounding box의 좌표값을 출력
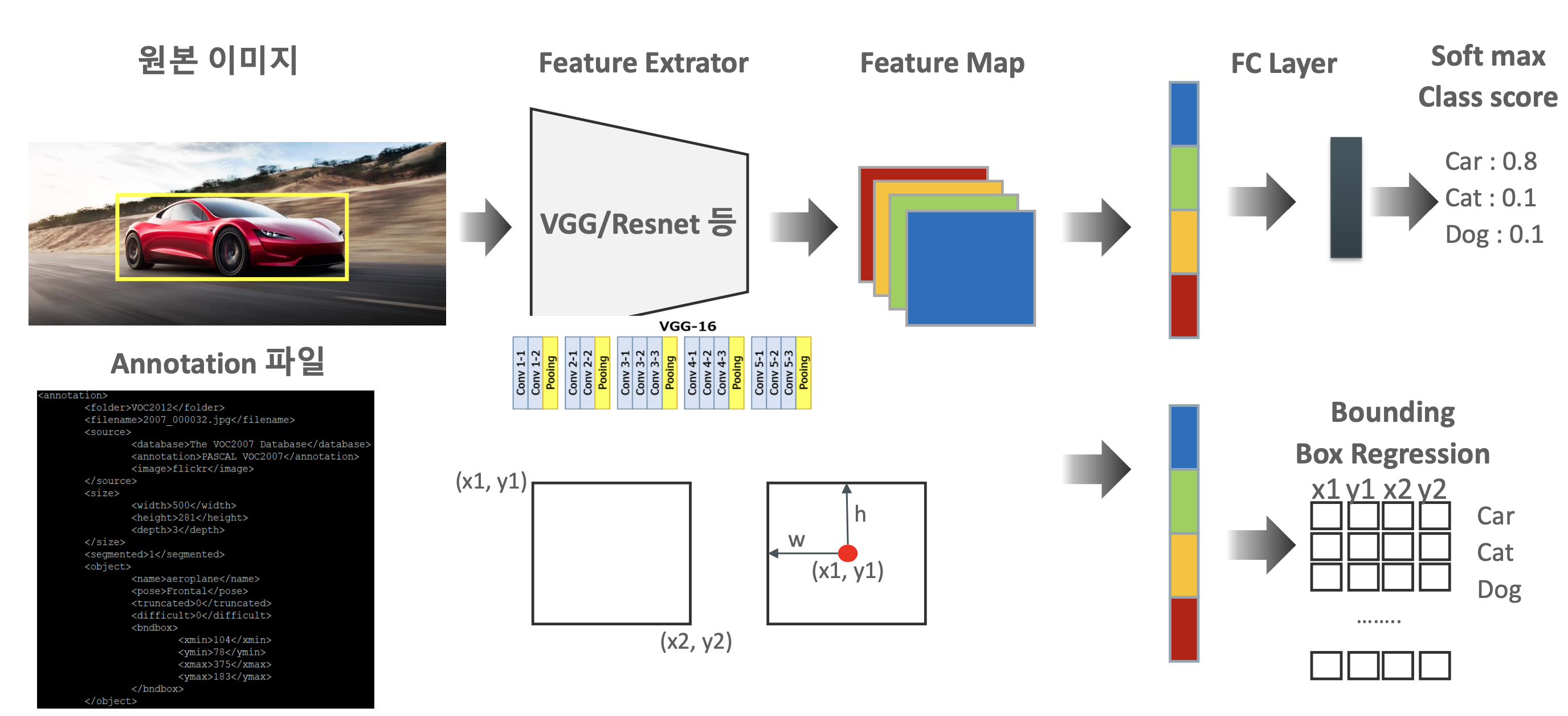
softmax와 같은 분류기를 FC layer에 포함시켜서 설명하는 경우도 있음
- 보통 feature map에서 말하는 채널의 경우 이미지를 표현할 때 RGB에 의해 3개의 채널로 표현
- 근데,, 경우에 따라 채널 수가 매우 많아지는 경우가 있는 거 같은데;;
4. Overview of Object Deteciton
- 2개 이상의 object를 검출
- 한 이미지에 비슷한 feature인 object들이 있을 때 bounding box regression에서 오류가 많이 발생
- Region Proposal
- Sliding Window
- Selective Search(SS)
Sliding Window

- 다양한 크기의 window를 sliding하는 방식
- window size를 고정하고 이미지 scale을 변화시킨 여러 이미지를 사용하는 방식
- object detection의 초기 기법
- object가 없더라도 무조건 모든 영역을 sliding, 수행 시간이 오래걸리고 성능이 낮음
- window 하나에 하나의 object를 detection하는 것이 주 목적이였으나, 경우에 따라 또다시 여러 object가 위치할 수도 있음.
Selective Search
x
- object가 있을 법한 영역(bounding box) 후보리스트를 작성해서 최종 후보를 도출
- 빠른 detection과 높은 recall 예측 성능을 동시에 만족
- flow에 따라 네트워크 안에 포함하여 구성할 수도 별도로 관리할 수도 있음
- 최초의 pixel단위 intensity 기반, graph-based segmentation > over segmentation
- 이미지의 컬러나 무늬, 크기에 따라 유사한 영역을 반복적으로 grouping 하는 region proposal

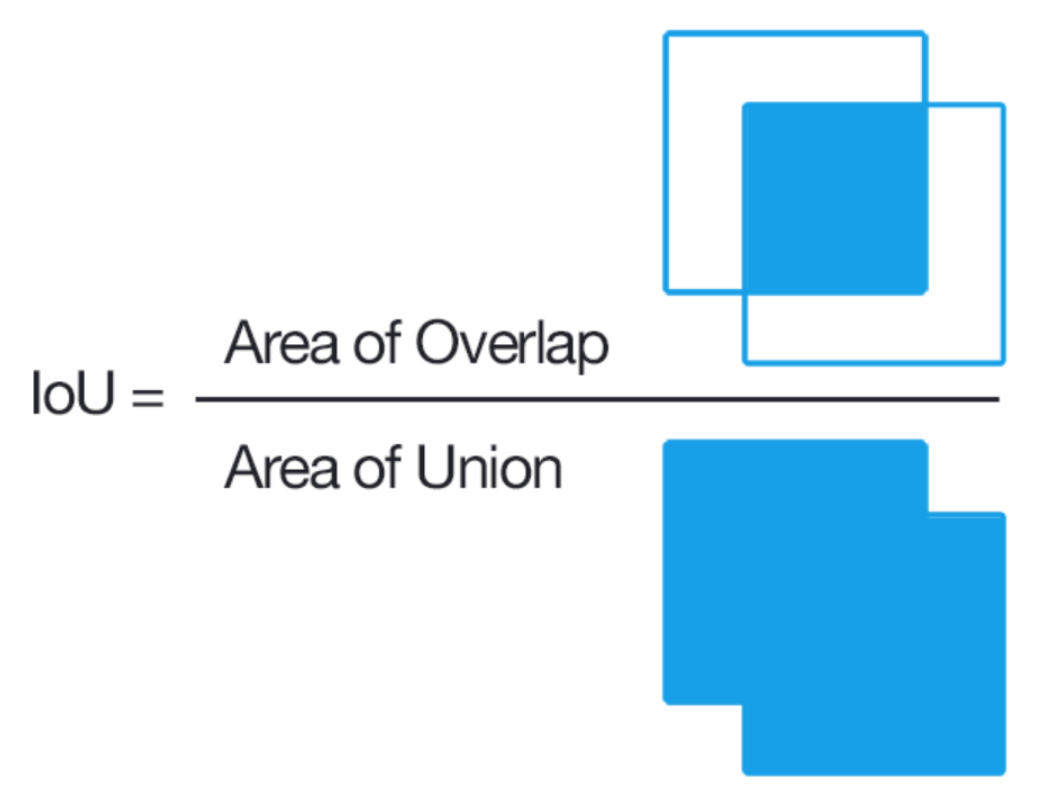
IoU(Intersection over Union)
- 실제 object annotated bounding box의 영역과 예측한 bounding box 간 겹치는 부분의 비율이 얼마나 되는지를 통해 잘 예측했는지를 평가 (ratio 0 ~ 1)
- compatition에 따른 IoU 활용
- PASCAL VOC : IoU 0.5 기준 성능 평가
- MS-COCO : IoU를 0.5 ~ 0.95범위에서 다양하게 성능 평가, 2차원 metric으로 성능 평가할 것으로 추정
NMS(Non Max Suppression)
- object 주변에 있는 bounding box중에서 가장 확실한 box를 제외한 나머지를 제외 시켜주는 기법
- object detection의 정확도를 올리기 위해 사전에 false positive인 bounding box까지 모두 추천한 후, 그 중 가장 확실한 box를 선택해주는 기법이 필요
- input
- Confidence score
- IoU score
- Confidence score가 높을수록, IoU가 낮을수록 더 많은 box가 제거됨.
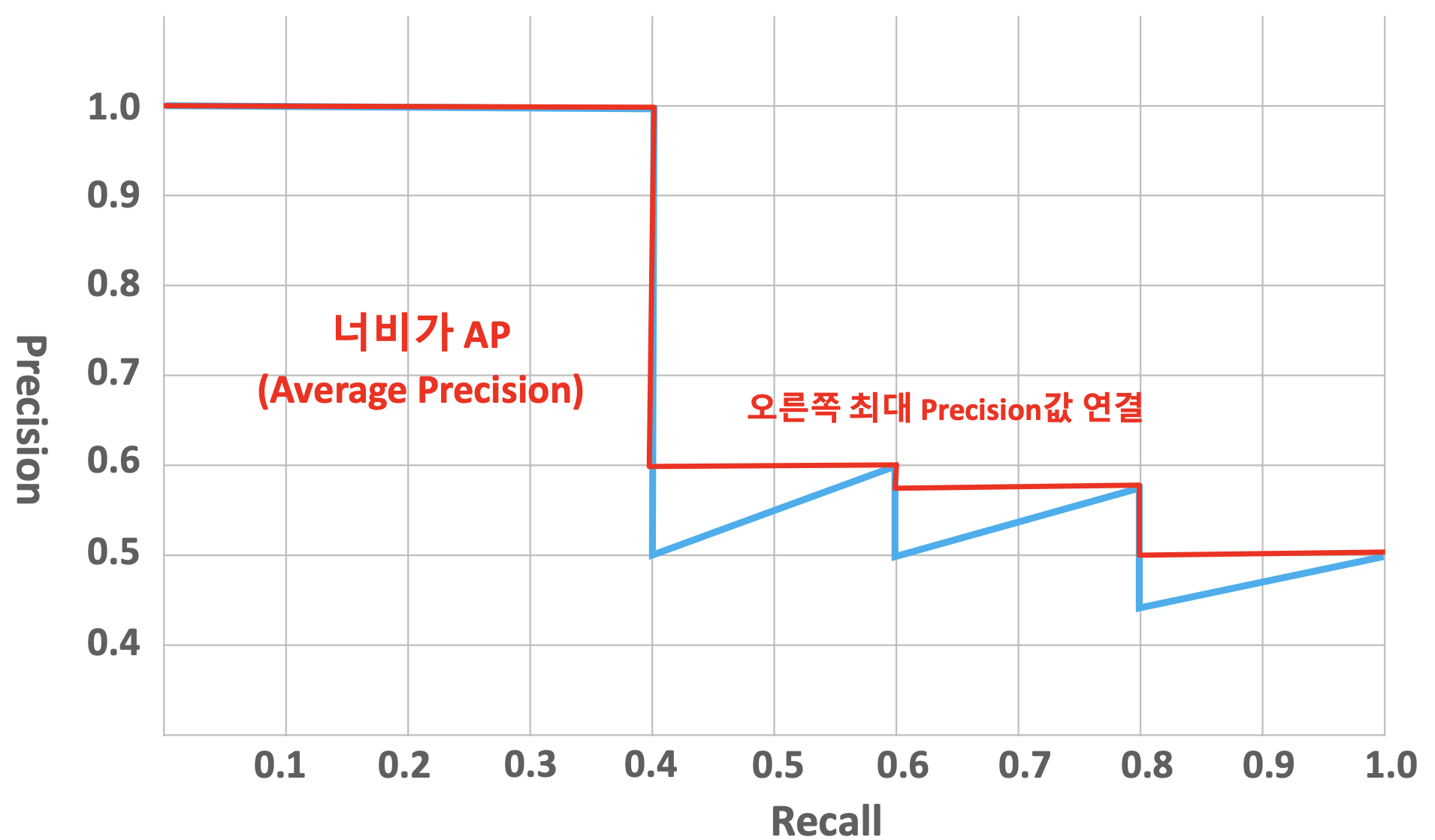
Object detection 성능 평가 metrics - mAP(mean Average precision) =~ AUC
- Recall 변화에 따른 Precision 값을 평균한 성능 수치
- IoU & Confidence score
- Confusion metrics
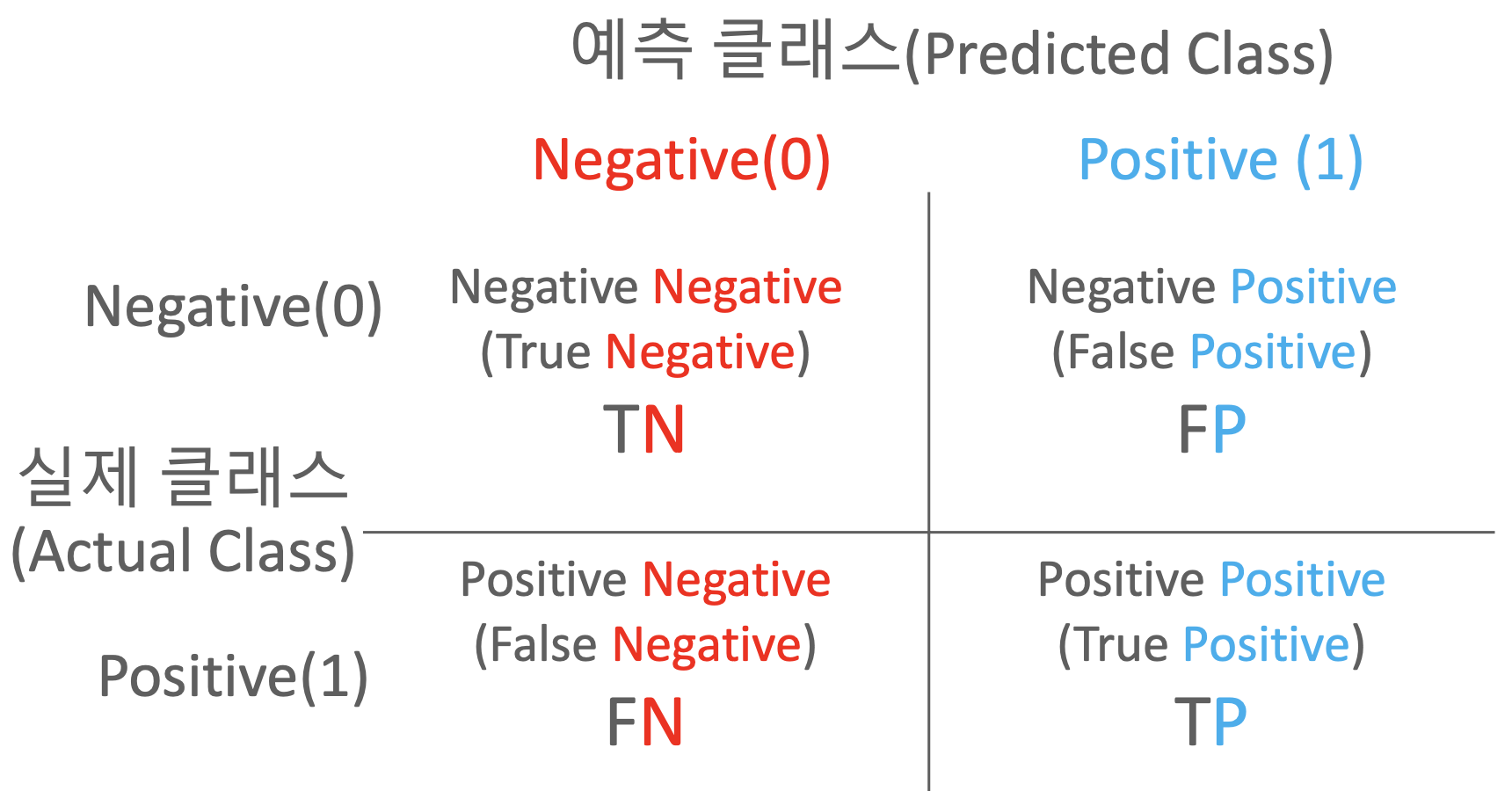
예측을 했냐? P(positive) 안했냐? N(negative), 그 예측 결과가 실제값과 일치하냐? T(true) 일치하지 않느냐? F(false)

- Precision-Recall curve(binary classification에서 잘 활용)
- Precision(정밀도) = $TP/(FP+TP)$
- Recall(재현율) = $TP/(FN+TP)$
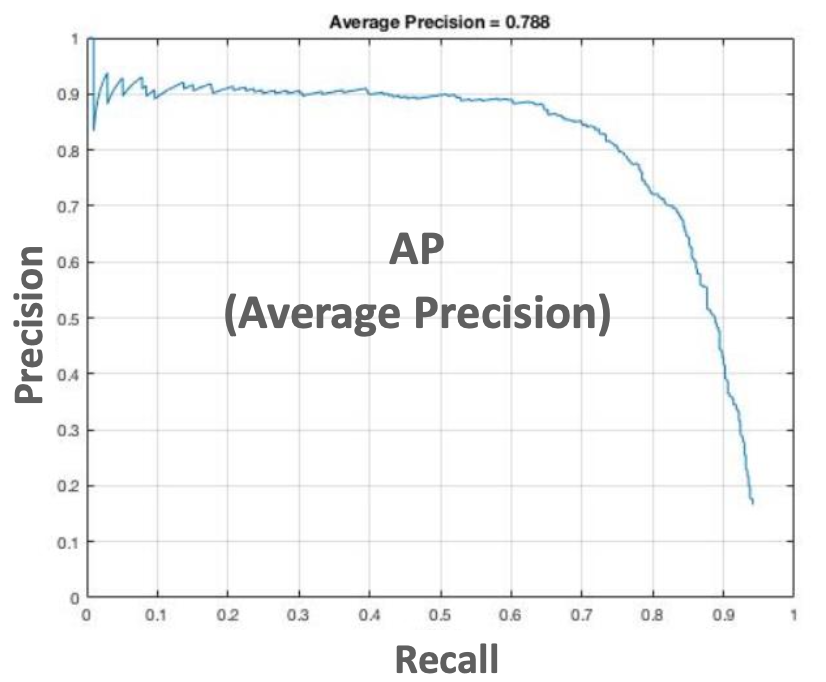
일반적으로 Precision-Recall curve는 지그재그 형태로 나타남
Precision & Recall Trade-off
- =~ Sensitivity & Specificity

AP(Average Precision)
- 하나의 object에 대한 성능 수치를 평가하는 지표
- 굳이 적용한다면 localization에 적용하는 것이 맞는 표현
mAP(mean Average Precision)
- object detection은 다수의 Object가 존재하기 때문에, 각 object의 AP를 계산 후, mean 계산
5. Object Detection & Segmentation을 위한 주요 데이터 셋
- PASCAL VOC
- object 유형이 20개 정도
- annotation : xml file
- MS-COCO
- object 유형이 80개 정도
- pretrained model 배표
- annotation : json format
- Google Open Image
- object 유형이 600개 정도
- annotation : csv format
PASCAL VOC
- Annotation : Detection 정보들을 설명 파일로 제공하는 것, 연결되는 이미지명을 포함한 각 object별 bounding box 좌표 정보(좌상단, 우하단)가 수록되어있음.
- ImageSet : train, validation set
- JPEGImages : Detection & Segmentation에 사용될 원본 이미지
- SegmentationClass : Semantic Segmentation에 사용될 이미지(별도의 Object 구분이 없음)
- SegmentationObject : Instance Segmentation에 사용될 이미지(object가 존재)


MS-COCO
- tensorflow api 등 open source 패키지들은 MS-COCO를 이용한 pretrained model 제공
- ID가 부여되었지만 데이터셋이 없는 것이 존재
- bounding box의 경우 좌상단 좌표와 width, height가 표기
- annotation file은 json file 하나로 구성되어있는데 one line 처리가 되어있음..
json format의 경우 별도의 주석 기능을 지원하지 않음. 굳이 넣는다면 절대 사용하지 않을 키 값을 만들어서 지정해주기.
- 이미지 하나에 여러 object들을 가지고 있어서 타 데이터 셋보다 난이도가 높은 데이터 제공한다는 장점이 있음.
6. Overview of OpenCV
Python 기반 주요 이미지 라이브러리
- PIL
- 처리 성능이 상대적으로 느림
- Scikit Image
- Scipy 확장, numpy 기반
- 전반적인 컴퓨터 비전 기능 제공
- OpenCN
- open source 기반 최고의 인기 라이브러리
- 컴퓨터 비전 기능 일반화에 기여
- 가장 중요한 부분 : image load(imread)할 때 RGB기반이 아니라 BGR기반으로 메모리에 load


import cv2
import matplotlib.pyplot as plt
#!/usr/bin/env python
img_array = cv2.imread('figs/CherryBlossom.jpeg')
#plt.imshow(img_array)
Image resolution, FPS, detection correlation
- Resolution이 높으면 detection 성능은 좋으나 FPS가 낮음
- 알고리즘 개선이 없다면 진보된 하드웨어가 필요…